SuperSONIC
The SuperSONIC project implements server infrastructure for inference-as-a-service applications in large high energy physics (HEP) and multi-messenger astrophysics (MMA) experiments. The server infrastructure is designed for deployment at Kubernetes clusters equipped with GPUs.
SuperSONIC GitHub repository: fastmachinelearning/SuperSONIC.
Why Inference-as-a-Service?
The computing demands of modern scientific experiments are growing at a faster rate than the performance improvements of traditional general-purpose processors (CPUs). This trend is driven by increasing data collection rates, tightening latency requirements, and rising complexity of algorithms, particularly those based on machine learning. Such a computing landscape strongly motivates the adoption of specialized coprocessors, such as FPGAs, GPUs, and TPUs. However, this introduces new resource allocation and scaling issues.

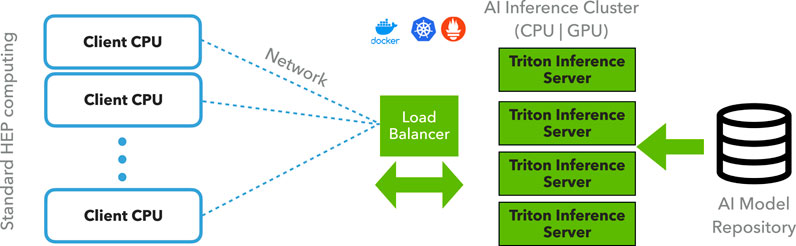
In the inference-as-a-service model, the data processing workflows (“clients”) off-load computationally intensive steps, such as neural network inference, to a remote “server” equipped with coprocessors. This design allows for optimization of both data processing throughput and coprocessor utilization by dynamically balancing the ratio of CPUs to coprocessors. Numerous R&D efforts implementing this paradigm in HEP and MMA experiments are grouped under the name SONIC (Services for Optimized Network Inference on Coprocessors).
Experiments that use SuperSONIC
The experiments listed below are developing workflows with inference-as-a-service implementations compatible with SuperSONIC. We are open for collaboration and encourage other experiments to try SuperSONIC for their inference-as-a-service needs.
|
CMS Experiment at the Large Hadron Collider (CERN). CMS is testing the inference-as-a-service approach in Run 3 offline processing workflows, off-loading inferences to GPUs for machine learning models such as ParticleNet, DeepMET, DeepTau, ParT. In addition, non-ML tracking algorithms such as LST and Patatrack are being adapted for deployment as-a-service. |

|
|
ATLAS Experiment at the Large Hadron Collider (CERN). ATLAS implements inference-as-a-service approach for tracking algorithms such as Exa.TrkX and Traccc. |

|
|
IceCube Neutrino Observatory at the South Pole. IceCube uses the SONIC approach to accelerate event classifier algorithms based on convolutional neural networks (CNNs). |

|
Deployment Sites
SuperSONIC has been successfully tested at the computing clusters listed below. We welcome developer help to add more computing centers to this list.
Purdue University: Geddes cluster, Anvil cluster.
National Research Platform (NRP): Nautilus cluster.
University of Chicago (ATLAS Analysis Facility): ATLAS Tier3 cluster.