The CMS High-Granularity Calorimeter (HGCAL), now under construction for the High-Luminosity LHC, is an imaging calorimeter with more than six million readout channels. All that granularity gives excellent spatial resolution for particle reconstruction, but it also creates a serious data-movement problem: trigger data has to be read out and transmitted at the 40 MHz LHC bunch-crossing rate. There isn’t enough bandwidth to send every channel off-detector at full resolution, so part of the data reduction has to happen right in the front-end electronics.
This work tackles that reduction step with a reconfigurable neural network ASIC that compresses data directly on the HGCAL trigger path. Each silicon sensor module produces 48 trigger-cell charge values, and the front-end concentrator chip (ECON-T) has to shrink that payload before it leaves the detector. The task is lossy compression: keep the shape of the energy deposit across the sensor, and drop what the trigger doesn’t need.
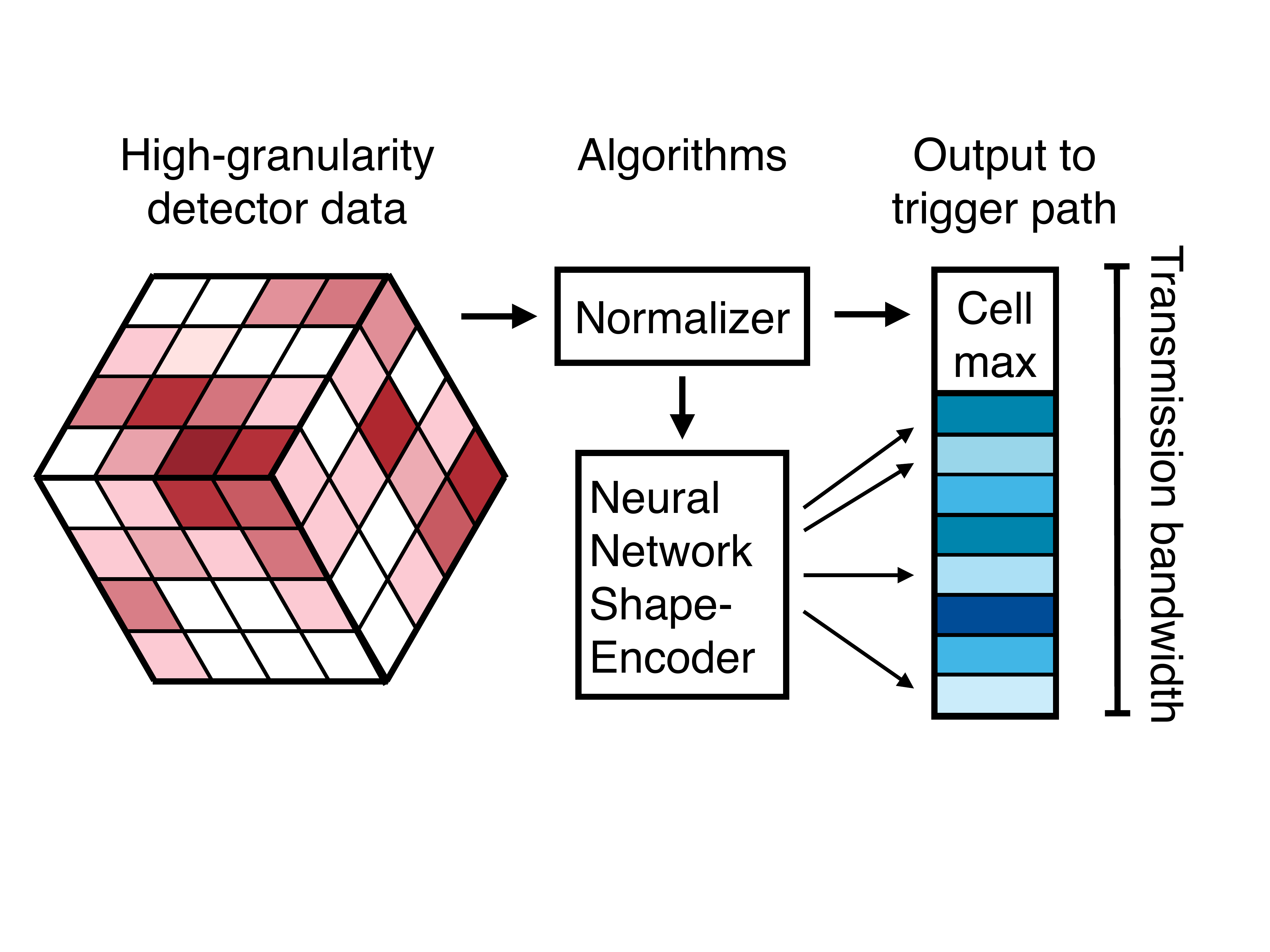
The compression algorithm is an autoencoder. Only the encoder ever runs on-detector: it takes the normalized trigger-cell pattern and maps it down to a small latent representation. The decoder is there only during training, where it forces that latent space to keep enough information to rebuild the original energy pattern; in a deployed system the decoding would happen later in the chain, off the chip.
What’s left on silicon is a compact “shape encoder” for the local calorimeter energy distribution.
The defining choice in the design is reconfigurability. The silicon is fixed once it’s fabricated, but the network weights are not: they’re loaded over an on-chip I²C interface. So the same chip can run different compression algorithms depending on where it sits in the detector, the local occupancy, or how detector and collider conditions change over time. It keeps much of the flexibility you’d expect from an FPGA while still buying the power and latency of a custom ASIC.
On the Fast ML side, the network is trained with quantization-aware training in QKeras, so the weight and activation bit-widths are optimized together with accuracy rather than truncated after the fact. hls4ml then translates the trained model into synthesizable C++, which feeds Siemens Catapult HLS for the actual ASIC synthesis. Reaching that point meant taking hls4ml beyond its FPGA origins: we extended the flow to drive Catapult and to target a low-power 65 nm CMOS process. The hls4ml-generated encoder is integrated with a SystemVerilog I²C peripheral that handles weight reconfiguration on-chip. As far as we know, this was the first neural network ASIC built with the hls4ml + Catapult HLS flow, and the Fermilab collaboration behind it fed directly into Siemens Catapult AI NN, announced in May 2024, which brings the same hls4ml-to-Catapult workflow to a much wider range of ASIC and SoC designs.
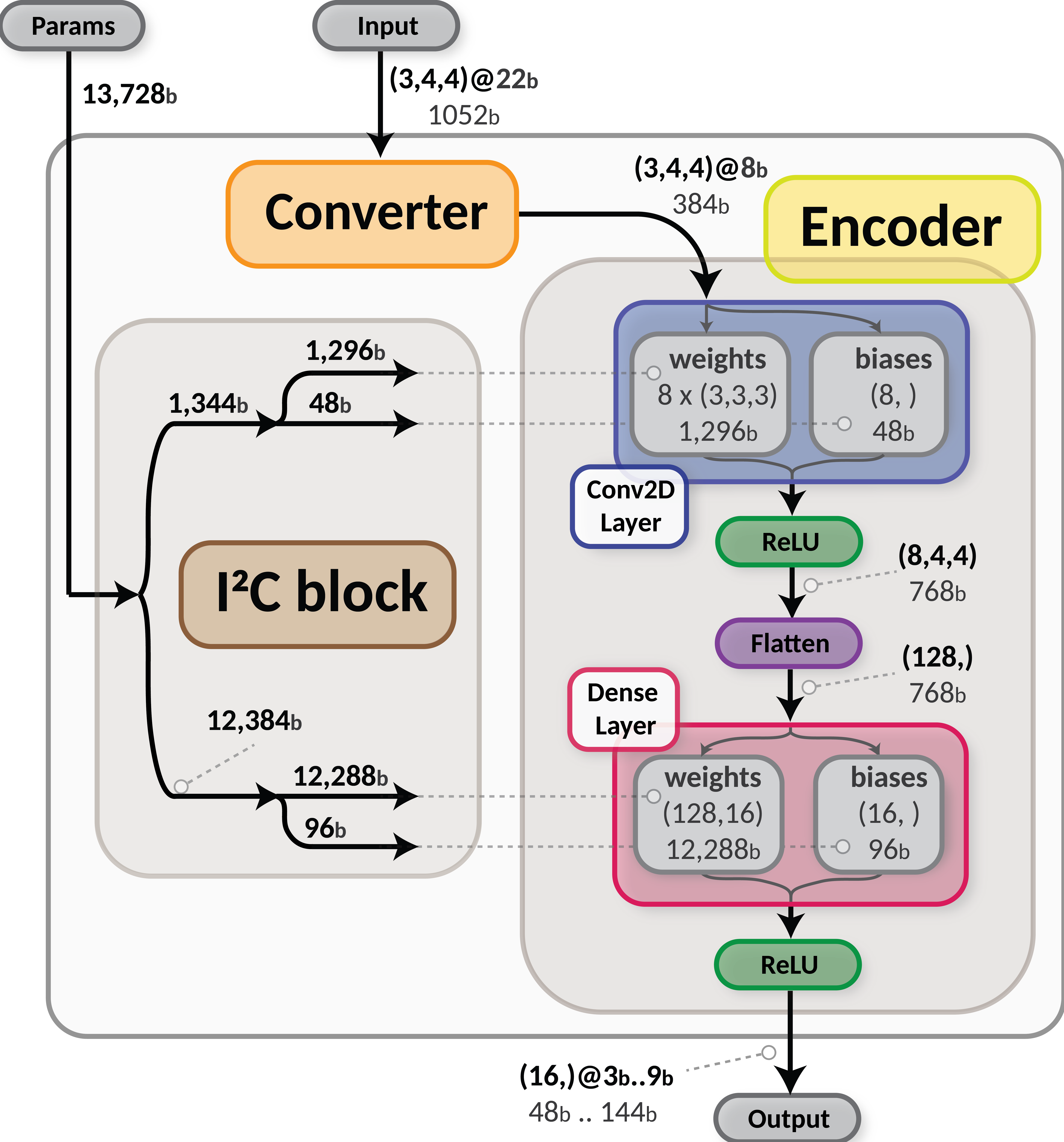
The digital design comes down to three blocks: a converter that normalizes the inputs, the hls4ml encoder, and the I²C peripheral that stores and updates the weights. Timing is set by the LHC clock: a new input arrives every 25 ns, and the chip produces its result within two bunch crossings, for a total inference latency of 50 ns. We carried the design all the way through synthesis and physical layout in a low-power 65 nm CMOS process.

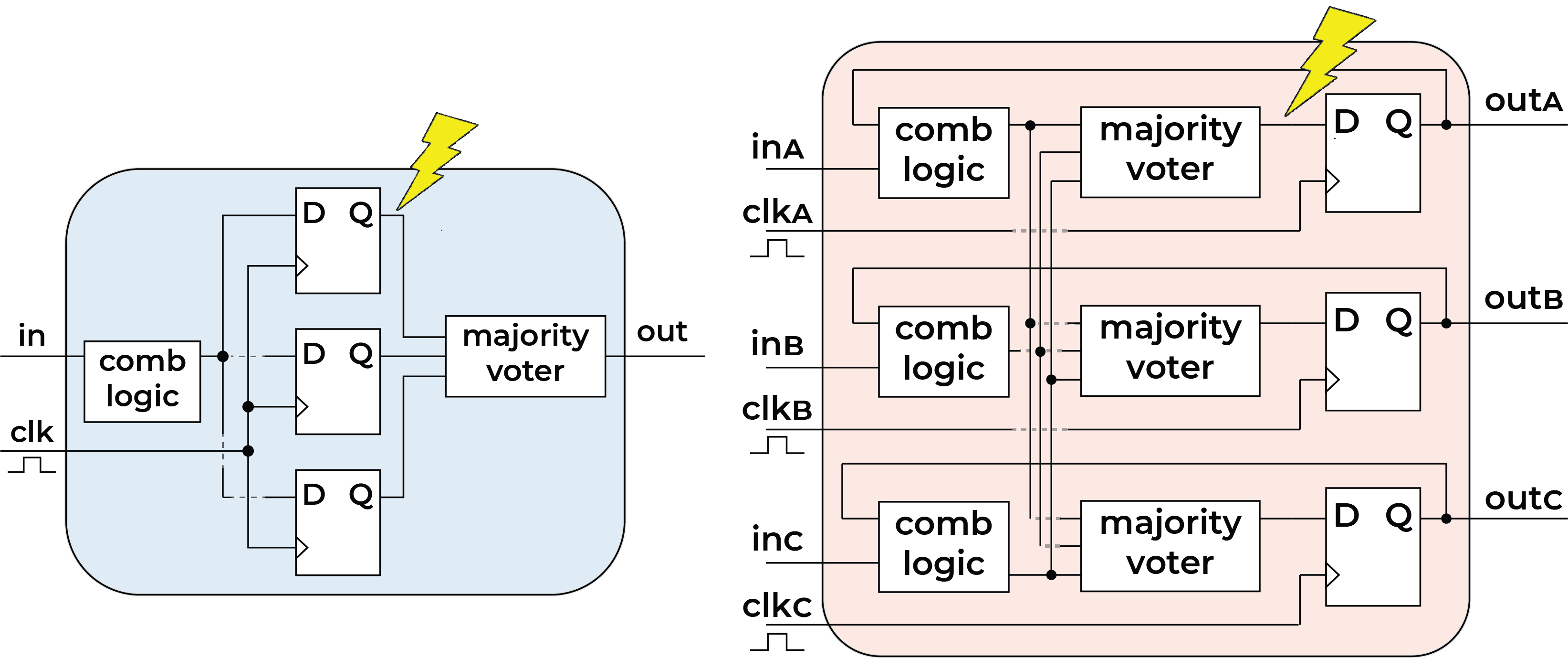
Living inside the detector also means surviving radiation, and that shaped the implementation as much as area and power did. The chip is designed to withstand a total ionizing dose of roughly 200 Mrad over its lifetime. Single-event effects are handled with triple modular redundancy: the encoder and converter datapath triplicate their registers and vote on the output, while the I²C peripheral that holds the weights uses full module triplication with autocorrection, so errors can’t quietly build up over time.
The final design lands at 50 ns latency, 2.38 nJ per inference, 95 mW, and 3.6 mm². Compared against an equivalent fully unrolled FPGA implementation, that’s more than an order of magnitude less power, and lower latency as well. To our knowledge it’s the first radiation-tolerant, on-detector neural network ASIC for particle physics, and for this community a complete Fast ML story end to end: from quantization-aware training, through hls4ml and Catapult HLS, to a validated and radiation-hardened layout.